1.资损概述
1. 1资损本质

1.2资损防控本质
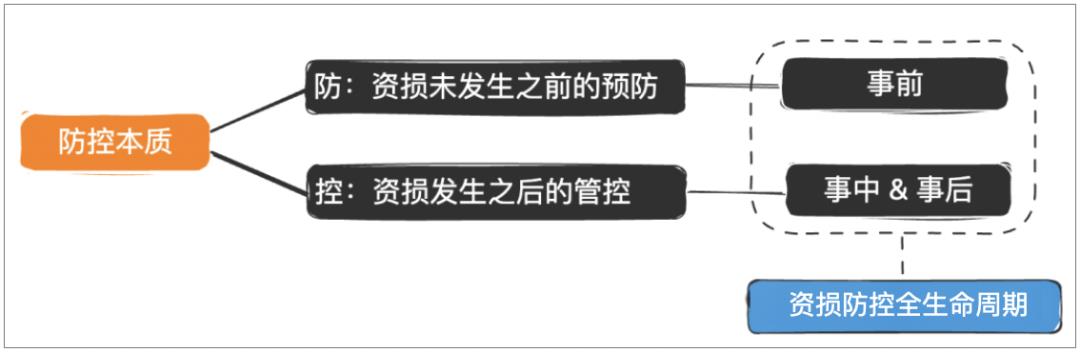
1.3资损防控全生命周期

1.4资损风险分类
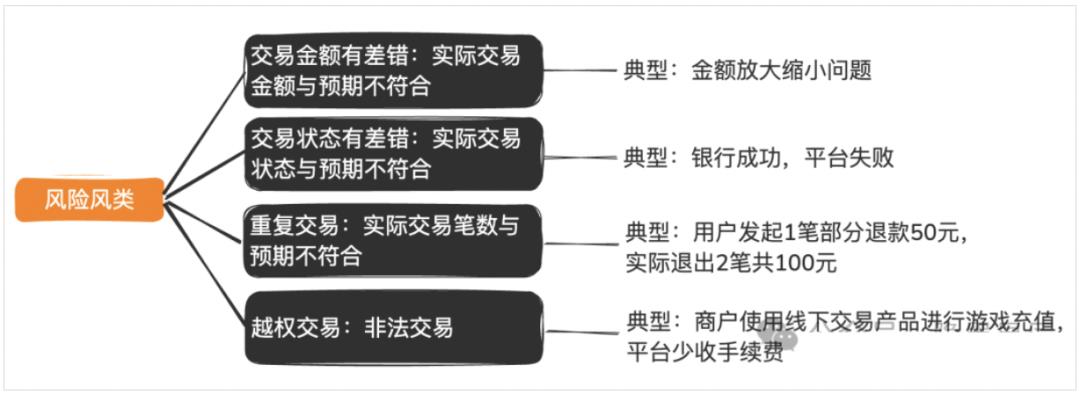
2. 常见场景及应对
2.1 金额放大缩小
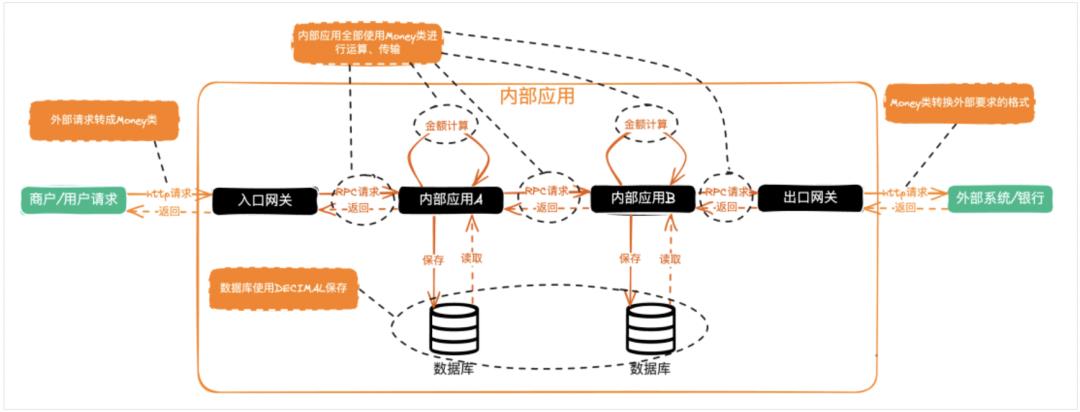
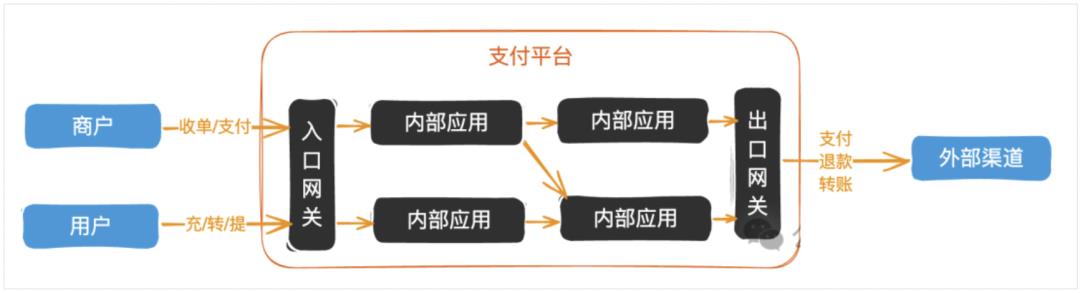
制定适用于公司业务的Money类来统一处理金额。
在入口网关接收到请求后,就转换为Money类。
所有内部应用的金额处理,强制全部使用Money类运算、传输,禁止自己手动加减乘除、单位换算(比如元到分)。
数据库使用DECIMAL类型保存,保存单位为元。
在出口网关外发时,再根据外部接口文档要求,转换成使用指定的单位。有些是元,有些是分(最小货币单位)。
2.2幂等击穿
如果一个支付系统不能保证幂等性,一笔交易可能变成多笔交易。比如向渠道发起部分退款50元,如果系统做了重试,且渠道不支持幂等,会被做为2笔交易处理,那么就会多退用户50元,资损发生。
幂等字段被变更,导致原有的幂等逻辑失败。无论对商户的收单系统,支付内部应用,外部渠道都有可能发生。
服务提供方在接口契约中一定要明确哪个是幂等字段。
内部应用的幂等字段变更,一定要跨域拉通对齐。
银行渠道的幂等字段及幂等条件一定要问清楚,不要想当然。
使用数据库唯一索引保存幂等字段。不要使用所谓的分布式锁来做幂等,只能用来辅助。
有能力的技术团队考虑建设幂等组件供全域使用。
特别注意在架构升级时,是否有变更幂等逻辑。
2.3流水号及短号重复
流水号过短场景下,需要拼接交易日期,如果1天之内有可能用完,让渠道升级接口。
短号场景下,查询回来的流水号,需要拼接渠道返回的交易日期及金额。
禁止网关生成流水号,全部使用上游业务系统发下来的流水号做为外部渠道的请求号。
系统升级时需要重点评估流水号变更逻辑,避免重复。
2.4返回码映射
调用渠道支付返回超时,平台推进到“失败”,但渠道最终处理成功,用户资损发生。如果是退款场景,平台资损发生。
渠道接口区分了“操作成功”和“业务成功”两个字段,但是平台只判断了“操作成功”就推进了单据到成功,资损发生。
商户调支付平台,内部各应用互相调用,支付平台调外部渠道,都有可能因为返回码映射导致资损发生。
需要明确哪些返回码是“业务成功”,哪些是“业务失败”,剩下的全部是“未知”。
只有明确是“业务成功”才能推进成功,明确是“业务失败”才能推进到失败。禁止把“超时”,“系统异常”,“交易重复”,“订单不存在”等返回码映射为失败。禁止把“操作成功”映射为业务成功。
流入类(扣用户钱)慎重推进到成功,流出类(给用户打款)慎重推进到失败。
2.5 乱序
如果渠道异步回调通知先回来,且在响应中返回“业务处理成功”,平台推进到“成功”,同步接口在异步回调之后才返回,且在响应中返回“处理中”,平台又推进到“处理中”。
渠道同步接口还没有响应回来,平台向渠道发起了查询,查询结果为“订单不存在”或“成功”,之后同步接口响应回来,但是响应结果和查询的结果不一致,如果处理不当,容易发生资损。
状态机设计务必要保证“终态不可变更”。也就不管同步接口先返回,还是异步通知先到,或者查询补单先查到结果,只要是推进到了终态(成功,或失败),那就不能再变更单据状态。
默认所有的返回都有可能是乱序的,系统设计要防重,不要依赖顺序性。
2.6越权/环境
如果对商户请求的参数校验不完善,商户有可能越权使用没有签约的支付方式。或者把线下场景(通常手续费低)的产品用于线上比如游戏交易(通常手续费高),平台少收手续费。
支付平台线下测试环境配置了渠道生产环境的参数,在做提现测试时,把平台真实的资金提取到了个人账户。
商户请求参数需要严格做校验,不但要校验基本的签名验签,还需要检查业务权限,避免商户越权操作。
禁止在线下环境配置渠道的生产环境参数。对渠道生产环境参数做黑白名单管控,通过系统能力来杜绝人为误配。
对用户的操作行为也需要严格校验权限和数据,避免A用户做支付时使用了B用户绑定的卡信息。
2.7数据库操作
严格执行“一锁二判三更新”的原则。不要使用所谓乐观锁。
根据业务形态综合决定是否引入分布式事务。对大部分业务场景来说,都不需要分布式事务。通过“最终一致性”已经能解决绝大部分业务场景。
如果一定要引入分布式事务,一定要对运行的机制非常清楚,尤其是事务悬挂。
2.8状态机
没有使用状态机设计思想,只是简单定义几个字符串表示“PAYING”, “SUCCESS”,“FAIL”等状态,然后使用if else 或switch case等写状态的流转。
状态机没有设计终态,或者终态仍然可以变更。典型的在乱序环境下,异步通知线程更新为“成功”,同步接口后返回,然后更新为“支付中”。
引入严格的状态机,明确某个状态在什么事件驱动下可以迁移到哪个目标状态。
要有终态概念,一旦到达终态,就不能再变更。如果数据异常,那就人工订正数据库的数据。
2.9 多线程与资源共享
一些service(服务)使用了类成员变量,而且是可写的,导致不同线程写入不同数据,引起资损。
引入了Threadlocal变量,但在入口和出口没有做重置和清理,导致不同线程误用另一个线程的数据。
为提高性能引入缓存,但是混用了特定用户的缓存数据。比如设计是只是缓存了公共数据,但是在开发中把单个请求的特定数据也放入了缓存中,导致后续线程误用数据。
严格禁止在service(服务)使用可写的类成员变量。
Threadlocal变量在入口和出口一定要做重置和清理。
所有缓存数据,需要明确是所有线程共享,还是特定用户的数据。全局缓存数据和个人缓存数据不要混在一起。如果要有个人数据的缓存,一定要有与个人强相关的明确的KEY。
2.10 兼容与灰度
最基本的要保证发布阶段的兼容:请求出去时:新代码+老数据。外部回调通知回来时:老代码+新数据。
所有DB变更,无论是结构变更,还是数据内容变更,全部都需要考虑兼容性。
所有架构升级,如果模型也做了升级,需要提供适配器,通过适配器同时兼容处理老数据,避免老系统长期无法下线。
2.11运营操作
使用技术手段进行预警。尤其是一些不符合常规的操作,要有一个黑名单规则集合。比如给每人发100元无门槛券,可无限领多次。
加入必要的审批流。为兼顾效率,可以按不同金额设置不同的审批权限。
严格校对领取权限,避免通过URL地址拼接参数,可以越权领取营销券。
实时监控券的领取和使用,比如对同一用户要有领取次数等监控。
3.监控与对账
3.1监控
3.2对账
3.3实时对账与离线对账
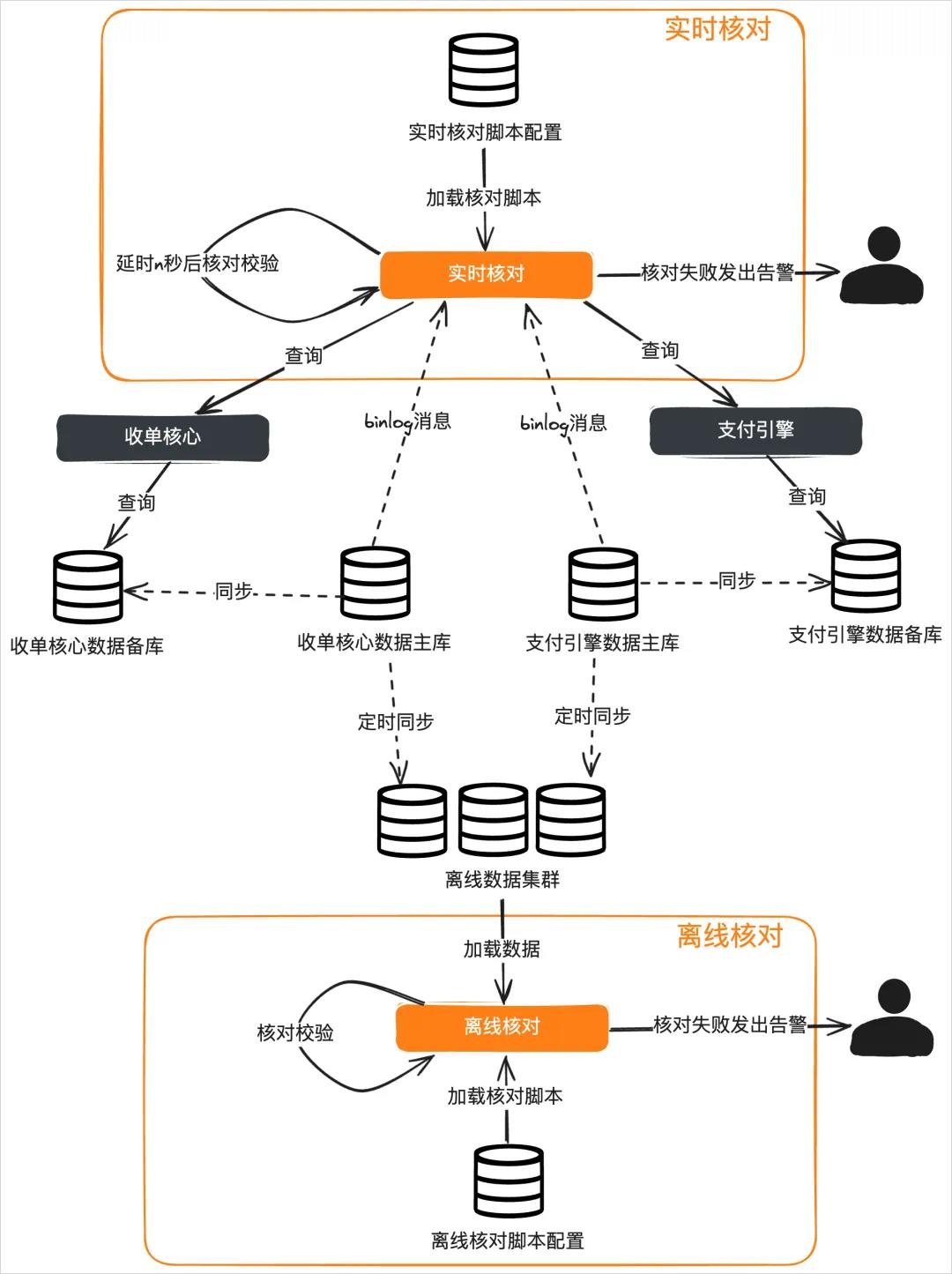
3.4三层对账

4.应急与复盘
4.1 应急
主管的经验通常更丰富,所做的决策考虑到的因子更多,知道什么样的故障应该怎么处理,如果需要协调其它部门,也更为高效。
一线工程师看到故障往往第一直觉就是先找问题根因,或者害怕主管责备,容易出现因处置不及时导致故障影响面扩大。
4.2复盘
故障定级:一般根据故障影响面来定等级。
时间线:故障从引入、触发、发现、止损、恢复等全部重要时间节点。
影响面:影响多少用户,多少金额等。
根因:因为什么引起,必要时需要贴上代码或技术方案。
反思:整个处置过程哪些做得好,哪些还需要改进。
待改进项:后续需要做什么,以杜绝类似问题,或至少发生类似问题时能处置得更高效。
责任人或责任团队。
尽量考虑通过技术手段来解决后续可能发生的类似问题。
尽量减少增加审批流程。
尽量不依赖个人的素质。
5.预案与演练
5.1预案
场景:明确预案处置的范围。
角色:一共有哪几个参与方,这几个参与方分别承担什么职责。
流程:什么角色在什么情况下执行什么样的操作。
5.2演练
6.产品设计要点
信息流与资金流匹配。尤其是跨境场景下,更是如此。
正向与逆向都需要考虑。
异常场景需要提前考虑,尤其是逆向。比如退款,如果出现因为超过渠道退款有效期或因为其它各种原因退不出去,怎么办?
7.全局通盘设计
结束语
某个银行使用6位短号,循环使用,在支付未成功时做了查询,查到老的订单是成功,推进到支付成功,给用户发货。
银行异步通知比同步返回更快,先推进成功,同步请求回来又推进到支付中,引起用户投诉。
金额传的是元,对接渠道的研发以为是分,发出前乘了100,导致金额放大100倍。
一个域修改了一个字段的取值,导致下游域的幂等失败,重复出款。