
在人工智能的世界里,“向量”是个至关重要的存在,它是支撑着大模型的理解、表达和信息处理能力的幕后英雄。从聊天机器人回答问题,到推荐系统,再到图片搜索,一切的背后都离不开向量。
今天我们就用中学生也能听懂的语言来聊聊“向量”那些事儿。
01
向量是个啥
从数学的角度看,向量是一个“有方向和大小的东西”,可以用数字坐标来描述。在计算机世界中,我们可以把向量简单地理解为一组“有意义的数字”,用来表示事物的特征。
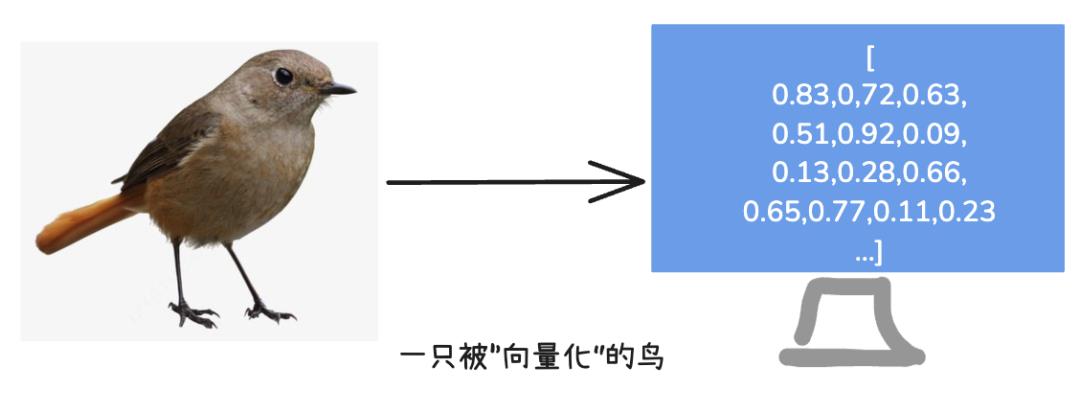
比如,我们要描述一只鸟,可以说:
“它有红色羽毛。它会唱歌。它的大小和手掌差不多。”
这些信息就可以被转化成向量,比如:
[红色: 0.913, 唱歌: 0.823, 大小: 0.534]
每个数字代表一项特性,这样鸟的特性就被数字化了。
无论是鸟、图片还是一句话,都可以用向量来描述。这种“通用的数字化语言”让计算机能理解复杂事物,也更利于AI中复杂的算法进行处理。
02
向量能干啥
向量除了有利于数学算法处理外,核心特点是能表示事物之间的“相似性”。
比如你有两个水果的向量:
苹果:[红色: 0.92, 甜度: 0.83, 圆形: 0.78]
草莓:[红色: 0.85, 甜度: 0.75, 圆形: 0.62]
虽然苹果和草莓是不同的水果,但它们的向量很接近。这表明它们有相似的特性,比如颜色和甜度。但如果你把“老虎”表示成向量,则和苹果的向量就不接近。通过比较向量的“距离”,计算机能快速判断哪些事物是相关的。
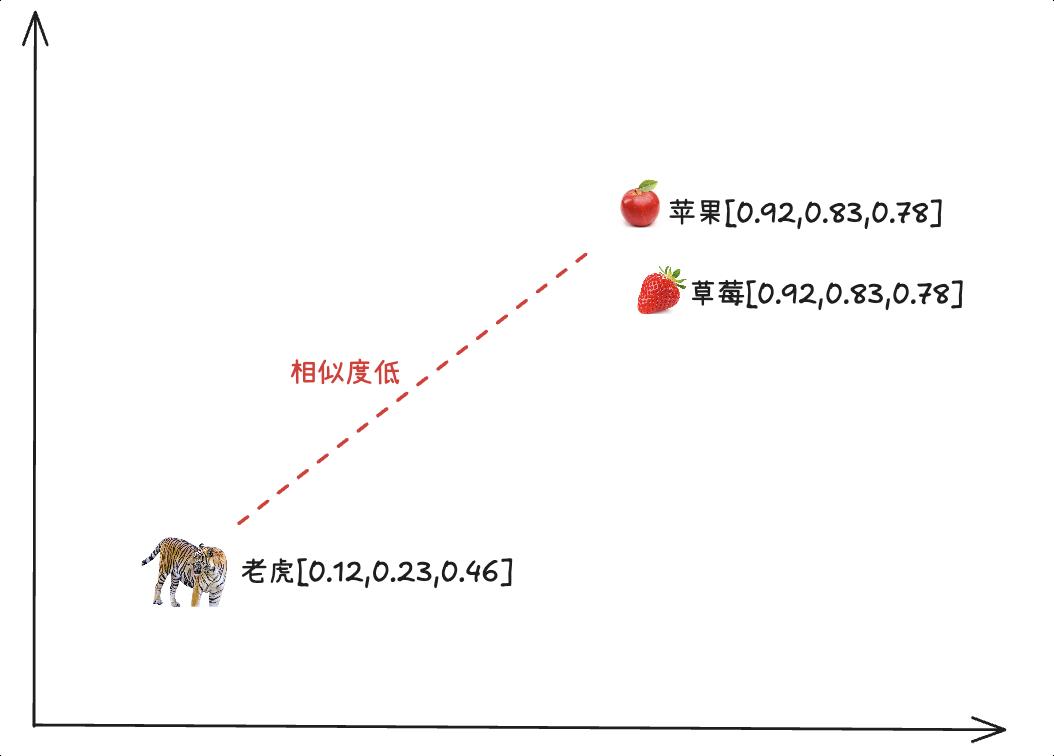
如果事物是用自然语言或者图片描述,当然也就可以比较文本或图片之间的相似性。
03
向量相似与文本相似的区别
普通搜索(如传统的搜索引擎)主要依赖关键词匹配,直接比对查询文本和文档中是否包含相同的文本与词汇。
比如查询:“人工智能如何帮助医生?”,现在有两个文档:
文档1:“AI技术正在协助医生进行疾病诊断。”
文档2:“机器学习在医疗领域用于提升诊断的准确性。”
普通搜索(基于关键词匹配):
查询关键词:“人工智能”,“医生”
匹配情况:
文档1:包含“AI”(人工智能的缩写)和“医生”,匹配成功
文档2:没有明确出现“人工智能”或“医生”关键词,匹配失败
所以搜索结果是文档1相关,并排除了文档2。
语义搜索(基于向量相似):
语义搜索通过向量表示捕捉文档和查询的语义相关性:
查询向量:“人工智能如何帮助医生”的语义向量
匹配情况:
文档1:高度相关,语义表示与查询向量相近
文档2:虽然没有提到“人工智能”或“医生”,但“机器学习在医疗领域提升诊断准确性”的向量与查询向量接近(语义相似)
所以语义搜索结果是文档1最相关,文档2语义相近,排名第二。
04
向量如何比较相似性
向量的相似性通常通过计算向量之间的距离来比较。距离越小,相似性越高。常用的算法比如余弦相似度来判断向量距离。
假设我们有两个文本的向量:
文本1:“AI帮助医生诊断疾病” → 向量为 [0.82, 0.61, 0.97]
文本2:“人工智能协助医疗诊断” → 向量为 [0.90, 0.73, 0.98]
计算余弦相似性,根据余弦相似度计算公式(不懂也没关系):
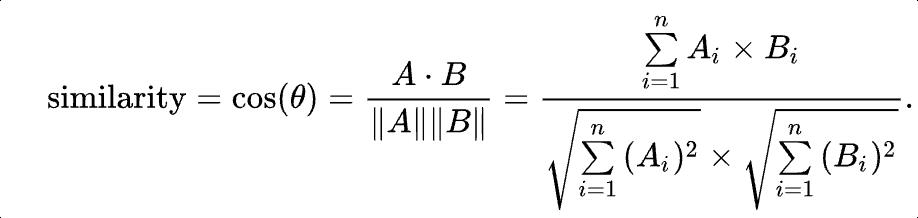
假设计算出相似度 = 0.99,非常接近1,说明两个文本的语义高度相似。
当然 ,在实际应用中,还有其他的相似度算法,可根据实际情况做选择。
05
那谁来负责计算向量?
答案是:嵌入模型。
简单来说,嵌入模型是一种专门负责把复杂信息(比如文字、图片、音频)变成数字向量的工具。比如你输入一句话:“我喜欢看电影。”嵌入模型会把这句话转化为一个向量:
[0.7, 0.2, 0.5, 0.9]
这些数字包含了这句话的核心意思,比如“喜欢”和“电影”是这句话的重点。
再比如给嵌入模型看一张狗的图片,它会分析图片的颜色、形状、轮廓等信息,生成一个向量:
[0.8, 0.6, 0.4, 0.7]
这些数字描述了图片的内容,比如“狗”“毛发”“背景”等。
为什么叫“嵌入”呢?“嵌入”这个词来源于数学,意思是把复杂的东西嵌套到一个更简单的空间中。嵌入模型就是把一段文字、一张图片,或者其他复杂的信息“压缩”成一组数字(向量),嵌入到计算机能够理解的世界里。嵌入模型就像是一个翻译官,把我们人类的数据“翻译”成计算机的语言。
06
谁来负责存储和比较向量?
答案是:向量数据库。
向量数据库是专门存储和管理向量的工具。传统数据库存储的是结构化数据(如姓名、年龄、地址等),而向量数据库存储的是“数字特性”数据,比如图片的向量、文档的向量等。
向量数据库的特点是能快速找到相似的向量。比如你上传一张“日落”图片,系统会根据向量相似性从数据库中找出其他接近的向量,进而对应到相似照片。
常见的向量数据库有 Milvus、ChromDB 和 Pinecone等。
07
所以向量在哪里应用?
我们最熟知的是RAG应用中使用向量来查询相似资料:
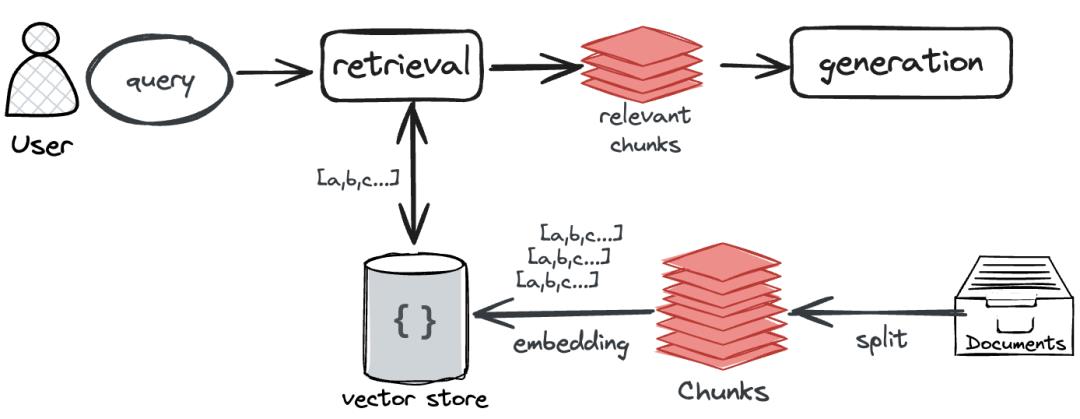
由于RAG应用是一种“边查边答”的应用,比如你问RAG应用:“C-RAG的基本原理是什么” 它需要检索出相关的资料段落(比如C-RAG论文),然后根据这些资料生成答案。
这时候,向量派上了用场:
首先把知识库里的文档分段转化成向量。比如:
段落1:[0.1, 0.7, 0.2]
段落2:[0.9, 0.1, 0.4]
段落3:[0.3, 0.8, 0.2]
然后,把问题“C-RAG的基本原理是什么”转化成一个向量。比如:
[0.2, 0.8, 0.1] (只是示例,真实的向量通常是几百甚至几千维的)。
接着,比较它与段落向量之间的“距离”(比如余弦相似度)。模型就能判断哪个段落最相关。
最后,大模型就可以使用最相关的段落来回答问题。
好比你在图书馆找书时,根据书的分类和关键词找到了最合适的参考书。而RAG本质上不就是“看着参考书回答问题”吗?
当然,除了在RAG应用中外,向量其实是贯穿整个大模型推理过程的重要角色。在大模型的推理计算过程中,输入输出其实都是以向量形式来进行的。毕竟,数值计算才是计算机擅长的工作。
08
向量有没有不足?
虽然向量很强大,但它也有一些不足:
高维计算成本高
向量通常是几百甚至几千维,计算相似性需要大量资源。
向量表达可能有误差
如果嵌入模型不好,生成的向量可能无法准确表达数据的特性。
向量数据库存储要求高
存储数百万甚至数十亿个高维向量,需要优化存储和检索效率。

向量是现代人工智能的核心工具,用数字化方式描述数据特性,让计算机能够理解和比较复杂信息。从大模型的推理到 RAG 技术的应用,向量技术无处不在,希望这篇文章让你对向量有了更加清晰的认识。





