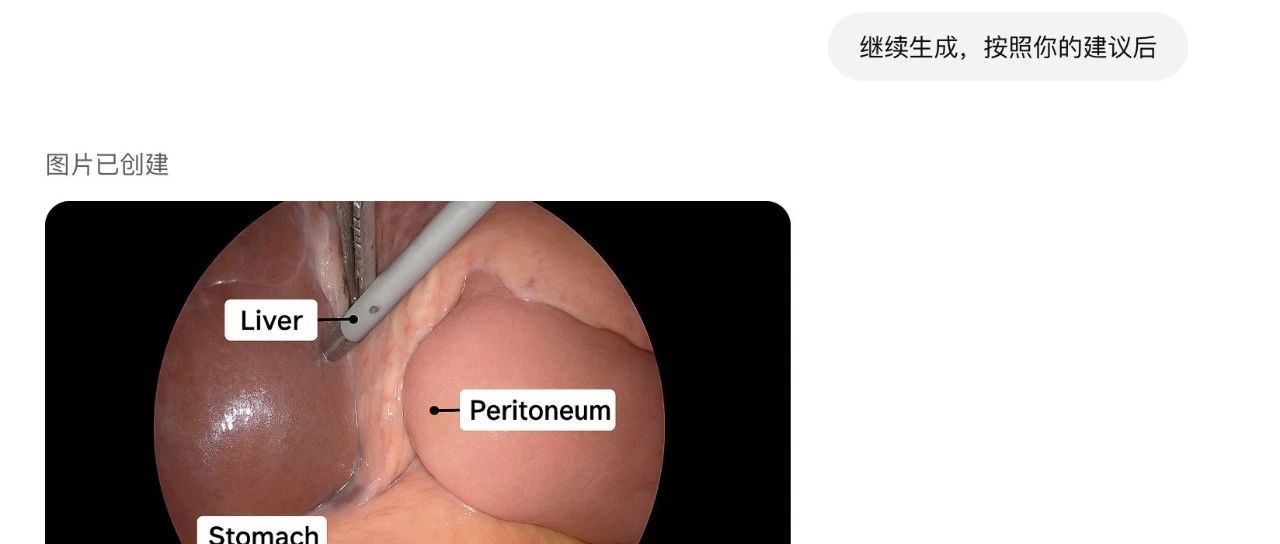
最近,谷歌一口气对AI模型能力做了一次大升级,其中最吸引我的是Gemini 2.0 Flash (Image Generation) ,这个模型对设计师来说,实用性很强。
然后谷歌这个模型也开放了API,可以很容易把它接入到comfyUI中,我自己试用后很兴奋,忍不住在我的社群里跟大家分享,太惊喜了!

可能有朋友还不知道Gemini 2.0 Flash是个啥模型?能做什么?
我先简单总结下:Gemini 2.0 Flash 最早是在2024年12月12号发布的,那时候只是作为一个实验性的发布,并不对我们普通用户开放。经过几个月的测试后,在3月12号已经测试通过,正式全面向所有人开放了。它能通过自然语言生成或编辑图片,和comfyUI有点类似,可控性很好。
可控性好就意味着在工作中将会变得实用,前段时间还跟腾讯的同事聊天,发现他们现在都已经要求团队的人必须会comfyUI了,招人也是有这个要求,能通过搭建工作流解决工作问题,对这块很是重视。
模型怎么用?
它的使用很简单,打开官方这个链接 :
https://aistudio.google.com/prompts/new_chat
然后选择Gemini 2.0 Flash (Image Generation) Experimental这个模型
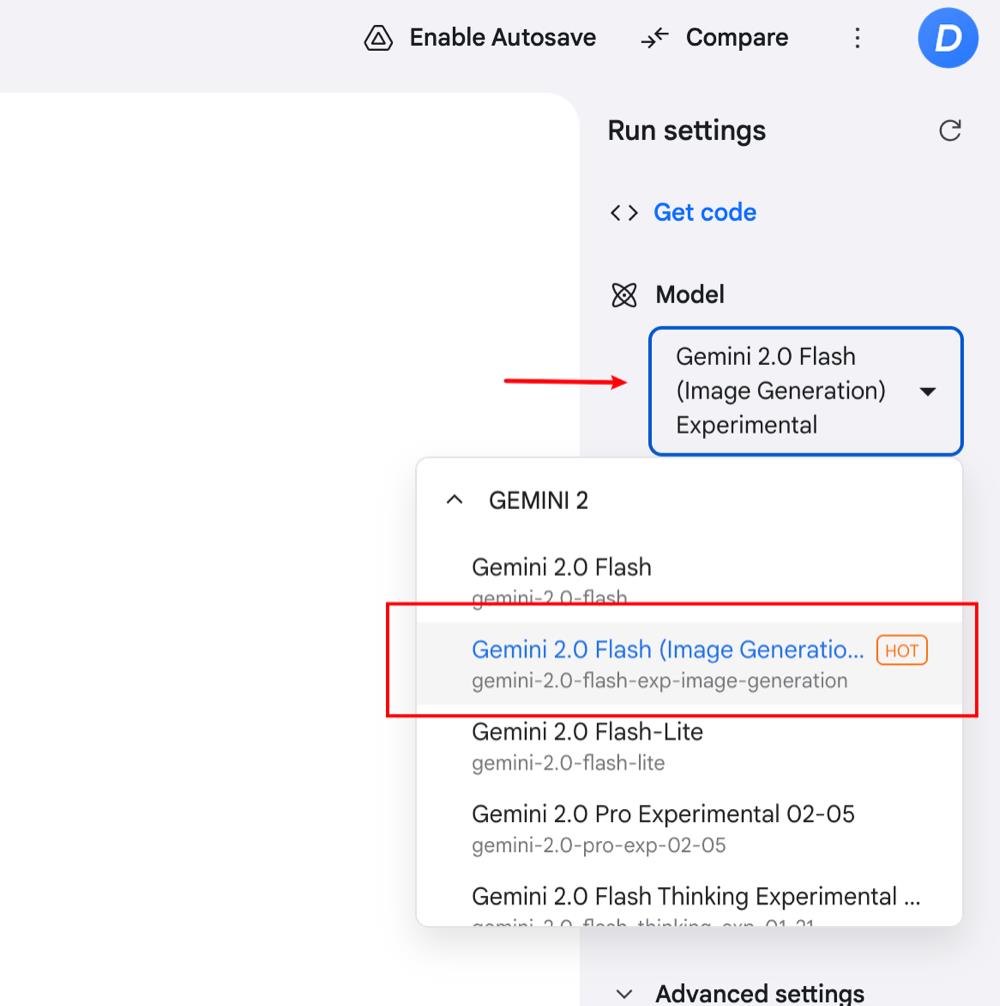
在主页上,它给了3个示例,可以分别点下这几个示例,就大概知道怎么用了。
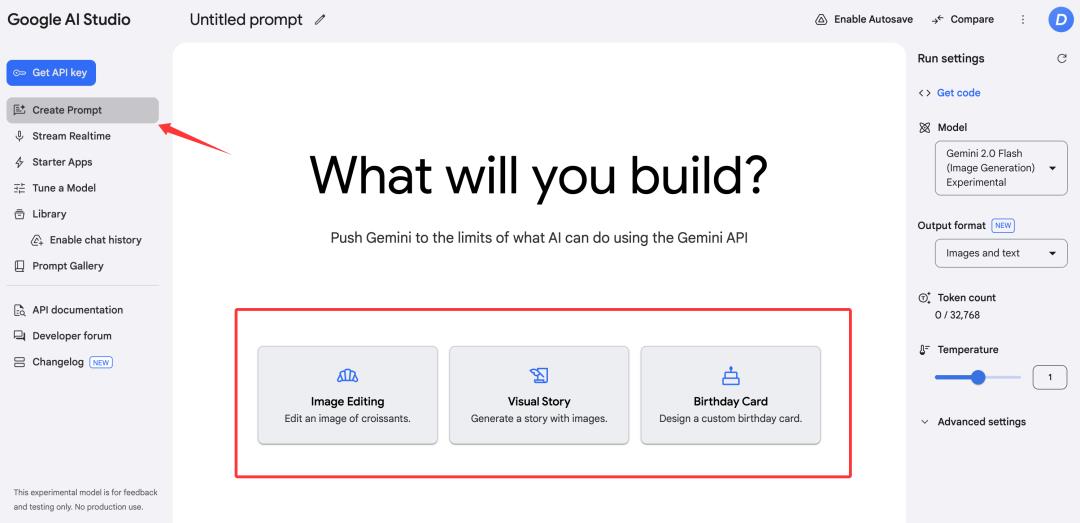
先快速说下官方给的这3个基础用法示例
1)图片编辑
用最直白的话就能对图片进行修改。
这里的提示词是:给牛角面包撒点巧克力。
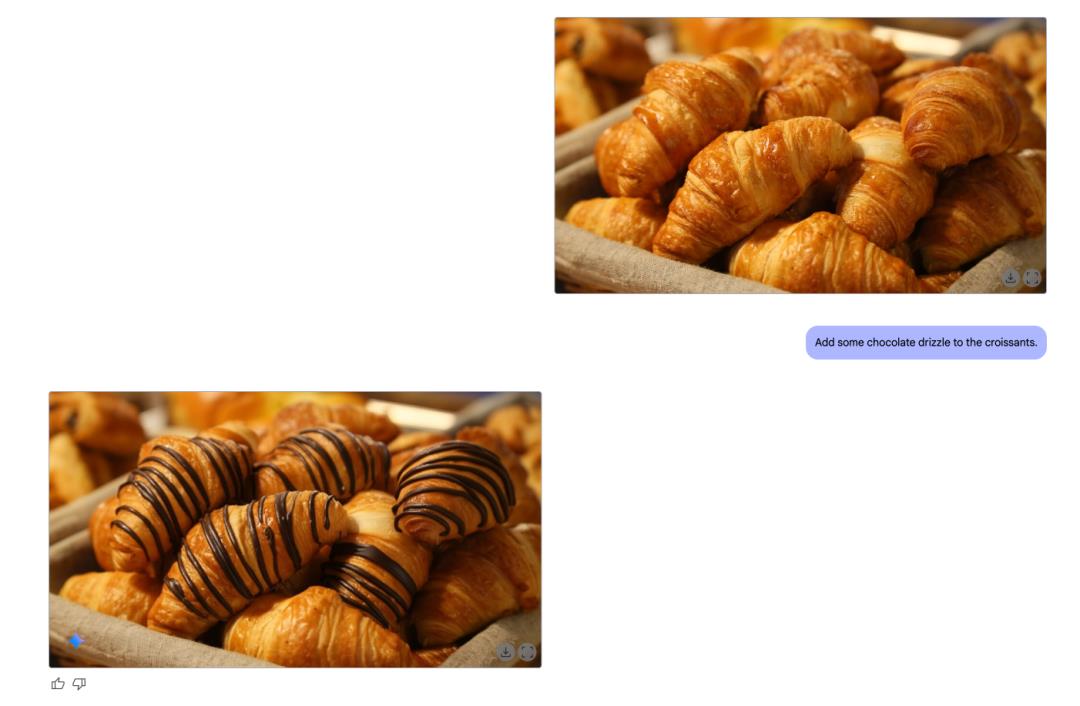
我们还可以继续用对话对图片进行编辑,比如“给这张图上面加点奶油”,如果觉得不大够,还可以“奶油再多一些”。

基本上它的生成就是指哪打哪,不会把原图搞乱,这就跟咱们在PS里修图挺像的了,非常实用,AI改图最怕的就是改完之后原图搞不像了,可控性至关重要。下次你老板再戳你屏幕的时候,直接让他帮意见打成文字,一分钟给他改好。
2)创建图片绘本
可以让它帮你写一段故事脚本,并且每一个场景配上一张图,且每个片段的图是连贯的。
这里的提示词官方给了示例:生成一个故事,关于一只小山羊在一个农场冒险的故事,每个场景对应生成一张配图。
点示例后,它很快就生成了9个故事场景,然后每个场景都会生成一张统一主角,统一风格的配图。效果惊人!
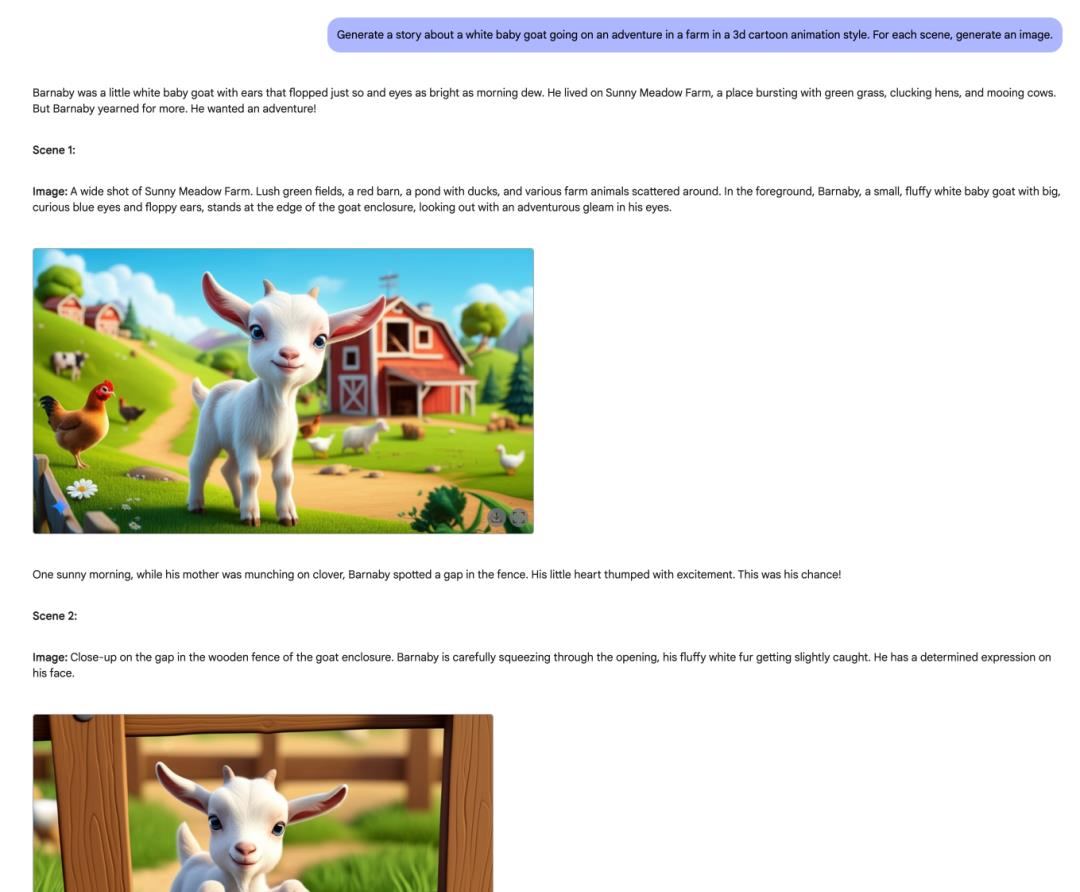
以后绘本生意估计不好做了。家里小孩想看绘本,咱们自己都能很快出一套,打印出来就能做成册了。亲手做出来给孩子的绘本,成就感肯定不一样,言传身教。
3)生成生日卡片
它还能通过最直白的对话,生成一张海报,文字内容我看了下完全正确,直接就能发给朋友了。

好,官方的几个示例都特别简单,自己去试下绝对能明白,没什么好说的。下面我要讲下它的进阶用法,我感觉这才是大招!这也是这个模型让我觉得最有用的地方,它提供了API的方式,可以随便免费插入到其他应用中,比如comfyUI。
我经常跟社群的朋友们说,一定要学会comfyUI,因为它真的能帮我们解决实际项目问题,我自己就在星球里已经打卡学习了100多天。但很多朋友的电脑配置带不动comfyUI,有心无力,现在有了谷歌的这个新模型API,只要你能在电脑上启动comfyUI,你的显卡多差都无所谓,一样能通过comfyUI工作流快速生成想要的效果。
具体在comfyUI里怎么接入这个模型?然后又有哪些进阶玩法呢?咱们继续说。
先启动comfyUI,如果你还不知道怎么安装,可以回翻我之前的文章。打开插件安装器,搜Gemini-API (https://github.com/tatookan/comfyui_ssl_gemini_EXP ),注意看最新更新的时间,装完之后重启comfyUI,它就会生效。

上面是连单张图的,如果你还想要通过2张图合并生成,可以装上这个节点:ComfyUI Gemini Flash (https://github.com/ShmuelRonen/ComfyUI_Gemini_Flash)节点。
然后双击comfyUI空白处,搜索gemini,把这个节点调出来
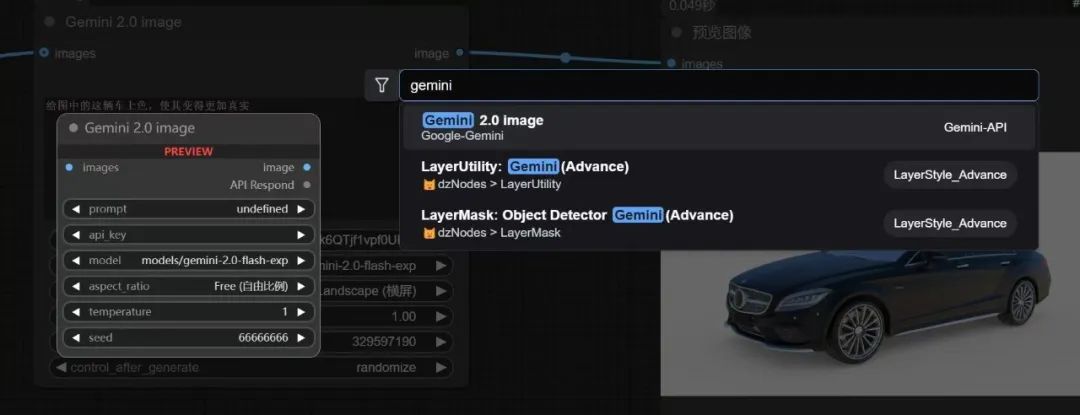
前面连上你想调的图片,后面接上图片预览,就能用起来了。
但在这之前,面板上还有一个api_key需要填,这个从哪弄到呢?
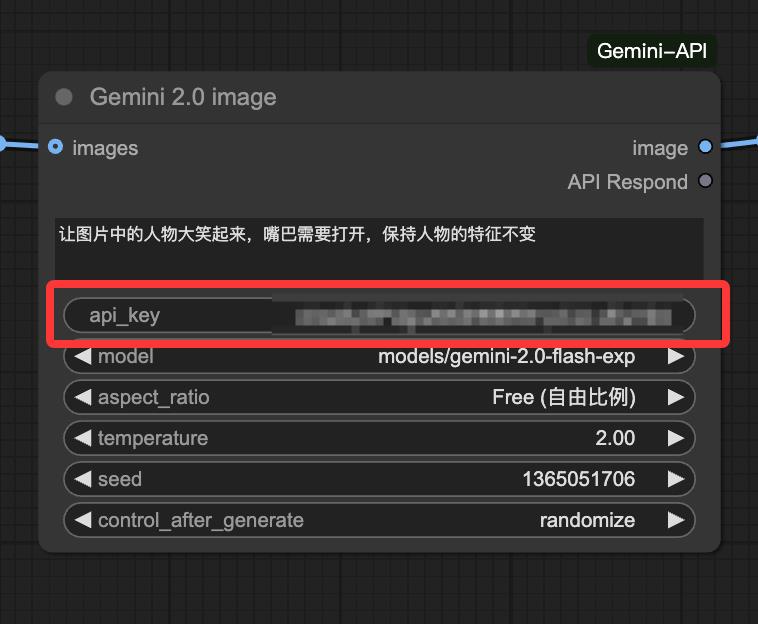
还记得前面打开的google AI studio吗?怕你忘了,地址再说一次:https://aistudio.google.com/prompts/new_chat
左上角有一个蓝色按钮,“Get API key” 。
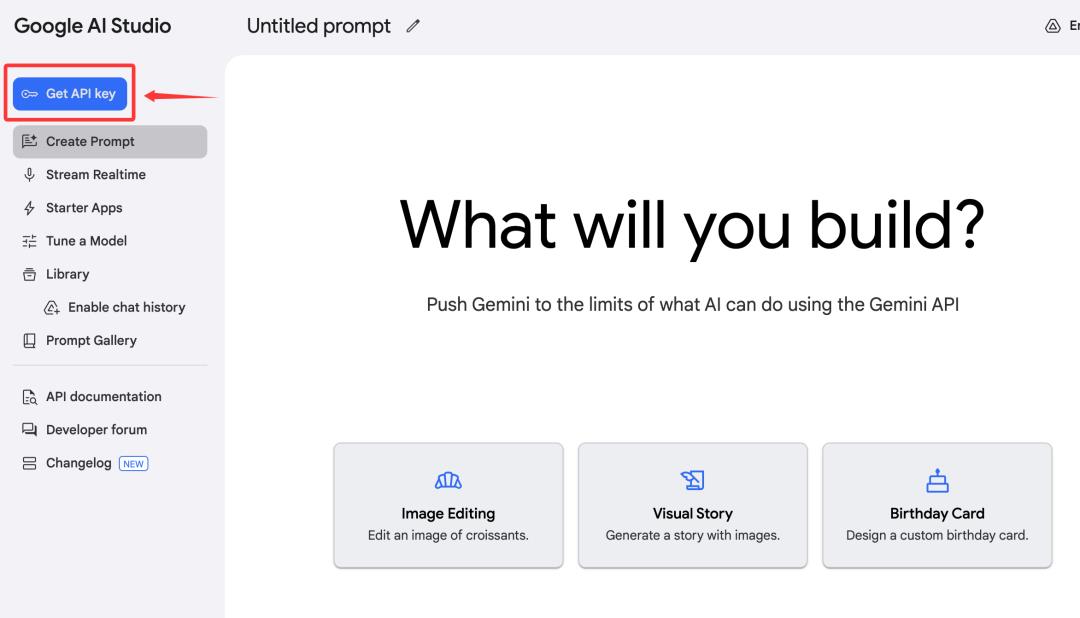
点中间的创建API秘钥
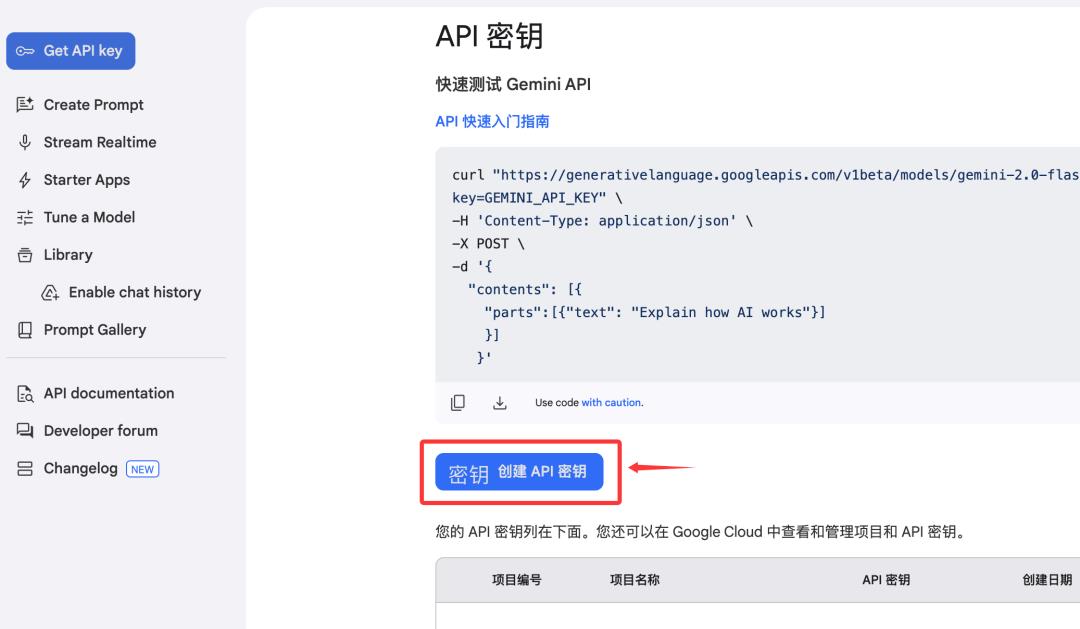
创建完之后,把这个秘钥复制上
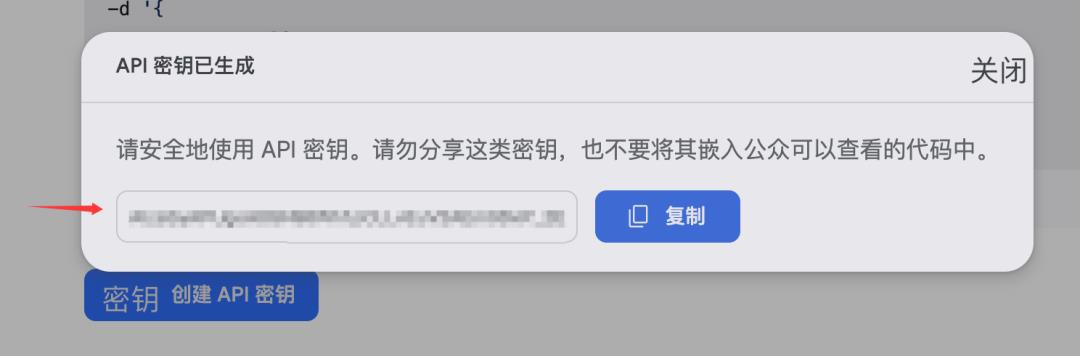
贴到comfyUI中刚才创建的节点里
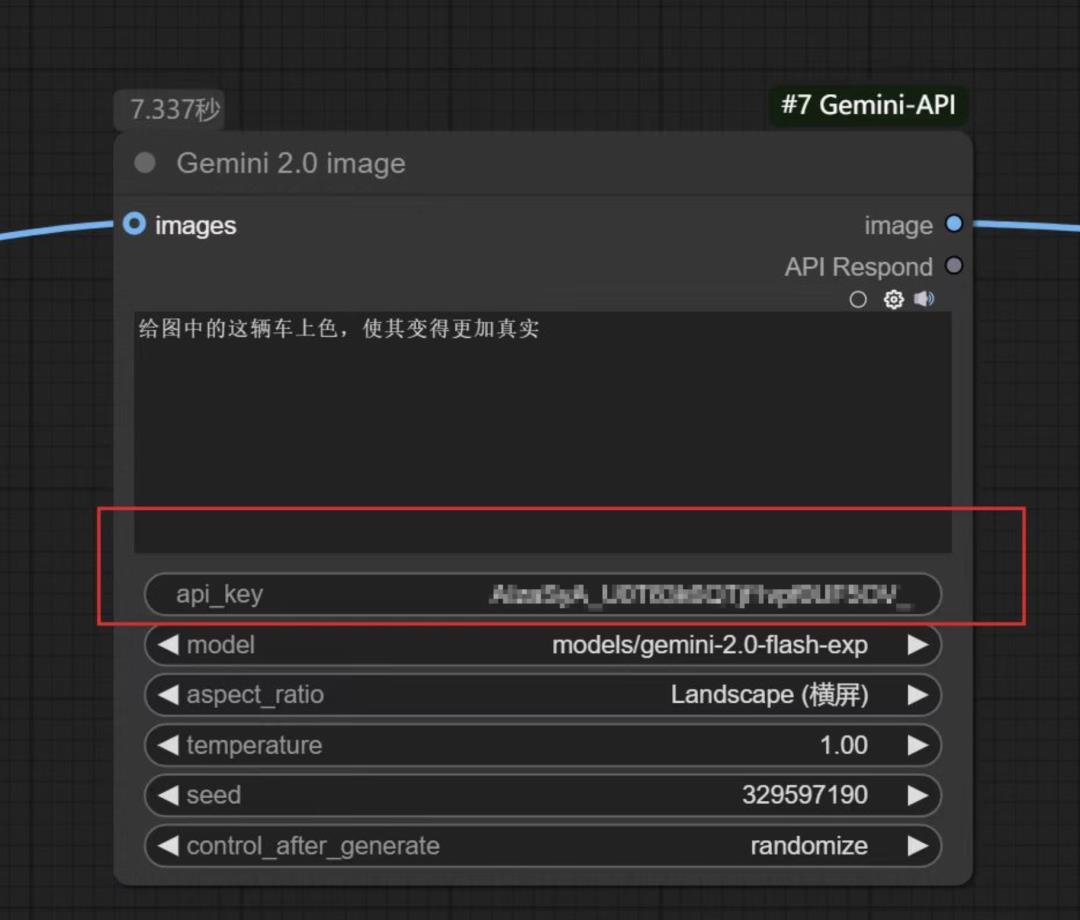
到这配置就完成了,没任何难度。
当结合comfyUI后,它能玩的东西就非常多了。相当于把之前可能需要一堆节点才能完成的事,现在用谷歌一个节点也能做。我给大家示例一些,其他的大家再发挥下想象力,把你想到的有意思的用途放在评论区。
1)给图片去水印
本来我想找一张车的白模给大家演示,但找到的图是带水印的,那就先去掉水印。

提示词:把这张图中的水印去掉,只保留车。
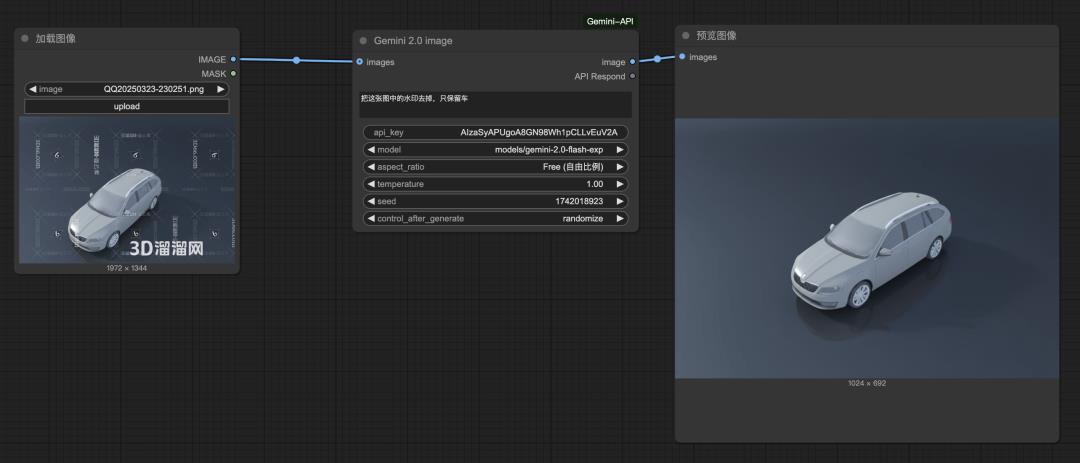
修改结果,发现它不仅把水印给去掉了,还把位置和光影移动到了更好的位置,图片的清晰度和质量都帮忙提升了。

2)上色+换背景
有了高质量白模图,咱们继续让这张图变得更真实。
给这张图上个材质,换个环境
提示词:给图中的车上个色,让它看起来更真实好看,车开在户外的公路上,路两边有山林,保留车的角度和特征。
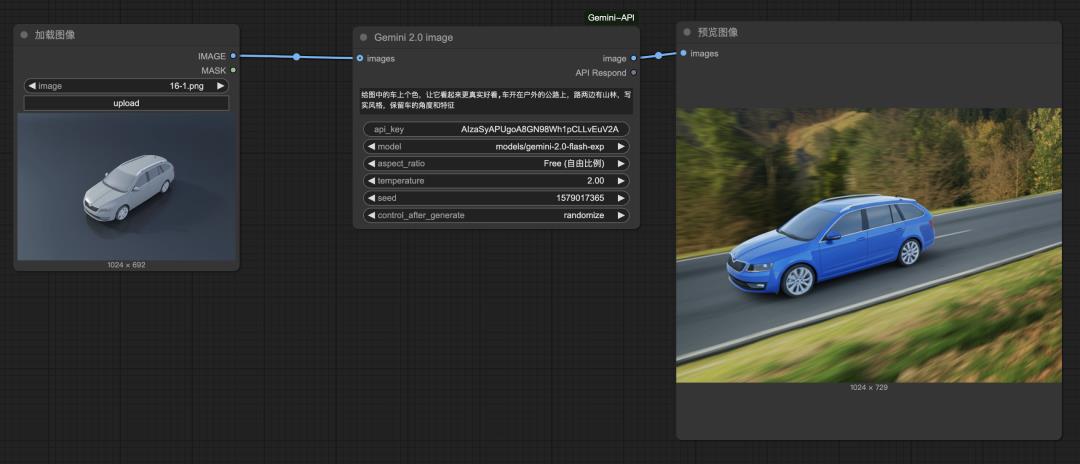
结果还行吧,基本特征算是继承了下来。

3)换衣服
给车上完色,咱们接着来做点更实用的事,给模特换衣服,这在电商领域经常用到。

提示词:给这位美女换一件白色衬衫
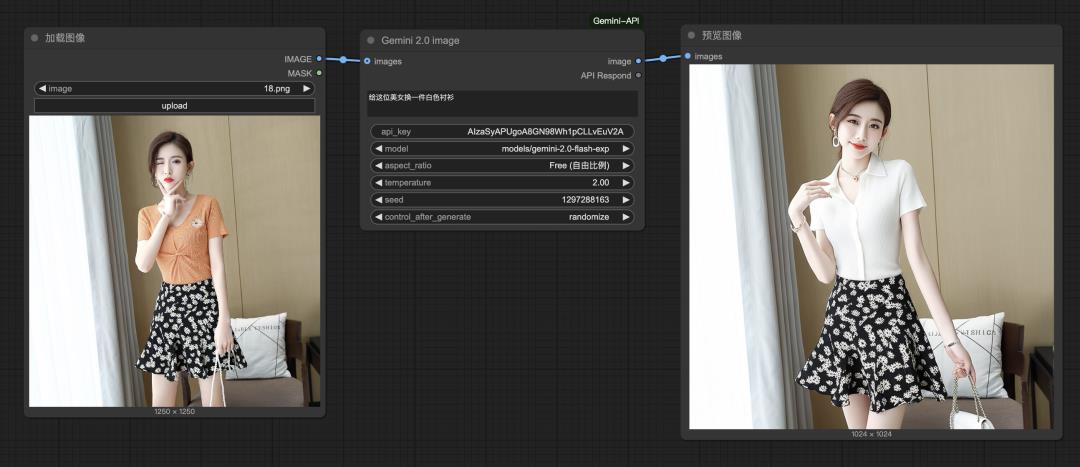
换完衣服,动作稍微有些变化,但画面的背景,人物的其他特征基本上得到了保留。

4)给一件衣服做一张广告图
假如我们有一件衣服需要把它做成一张宣传图。

提示词:给这件衣服添加一个小孩子模特,做出一张电商广告图,保持衣服的一致性

5)给人物换个表情
以前在comfyUI中换表情,调起来挺麻烦的,现在接入这个API后,换表情不要太容易,而且效果还不错,人物特征保持的特别好。
比如我拿哪吒来尝试,让他张嘴笑起来。

提示词:让图片中的人物大笑起来,嘴巴需要打开,保持人物的特征不变。
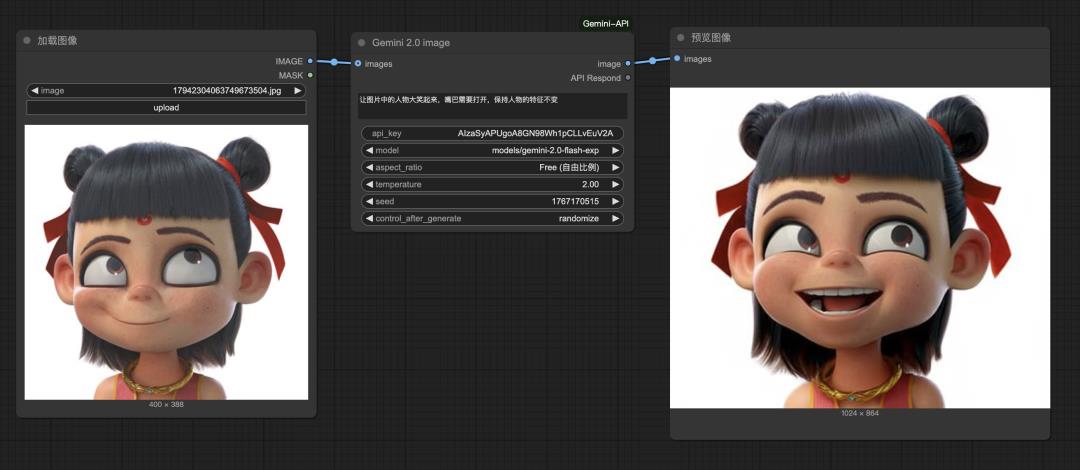
修改结果

上面这些操作,你也可以不用comfyUI,直接用谷歌的那个对话框也能搞定,只不过在comfyUI里有批量或者其他更多操作的时候,会更方便一些。
AI的发展,其实一直都在降低技术学习成本,comfyUI学习对很多人来说太复杂,我就知道早晚会把它的难度打下来,只是没想到这么快。
果然在AI世界,每天都在发生巨变,我们要做的就是保持关注,积极接纳,多用多学习。一起适应这个正在发生巨变的世界。