李宏毅:从零开始搞懂 AI Agent

引言:AI Agent 是什么?为什么它突然火了?
最近科技圈的热门话题里,"AI Agent"绝对是个高频词汇。
其实这个概念早在2023年就掀起过一波热潮,当时AutoGPT和MetaGPT的横空出世让人们对它充满期待。
如今,在大模型技术持续升级的推动下,2025年AI Agent重新成为行业关注的焦点。
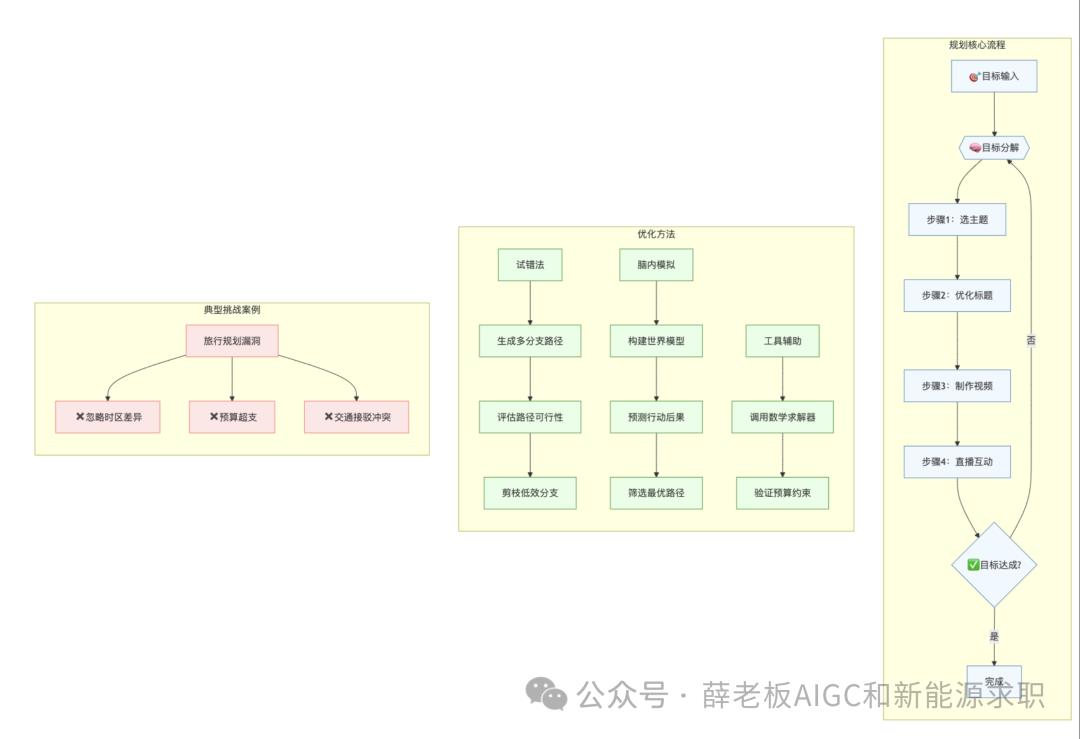
你可以把它理解为一个拥有自主决策能力的智能管家。比如你只需要交代一句:"帮我订一张2000元以内的上海机票",它就能自动完成查询航班、比较价格、填写信息等一系列操作,最终帮你搞定机票。
这正是AI Agent的精髓所在——
它不会被动等待指令,而是主动寻找解决方案。
这与我们熟悉的ChatGPT、Deepseek等对话式AI有所不同。后者更像是一个"有问必答"的聊天伙伴,而AI Agent则是一位能够"主动出击"的智能执行者。
一、AI Agent 的本质——从「听话」到「主动」
1.1 AI Agent 和普通 AI 的区别
要理解AI Agent和普通AI的区别,我们可以从它们的工作方式来看。
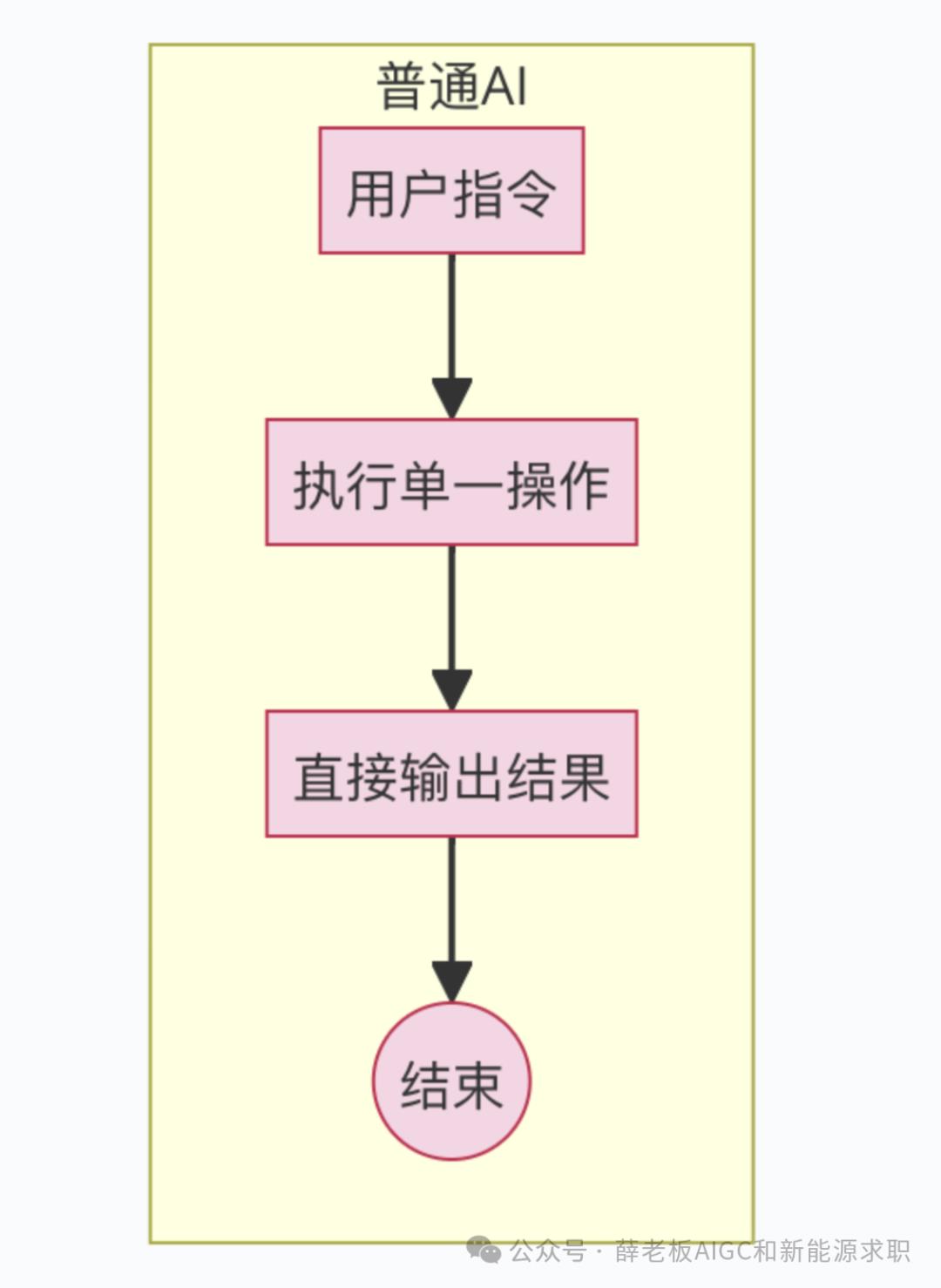
举个例子,如果你问ChatGPT:"AI Agent用中文怎么说?" 它会直接回答:"AI Agent的中文是'人工智能代理'。" 这就是传统AI的工作模式——你输入指令,它给出结果,任务结束。
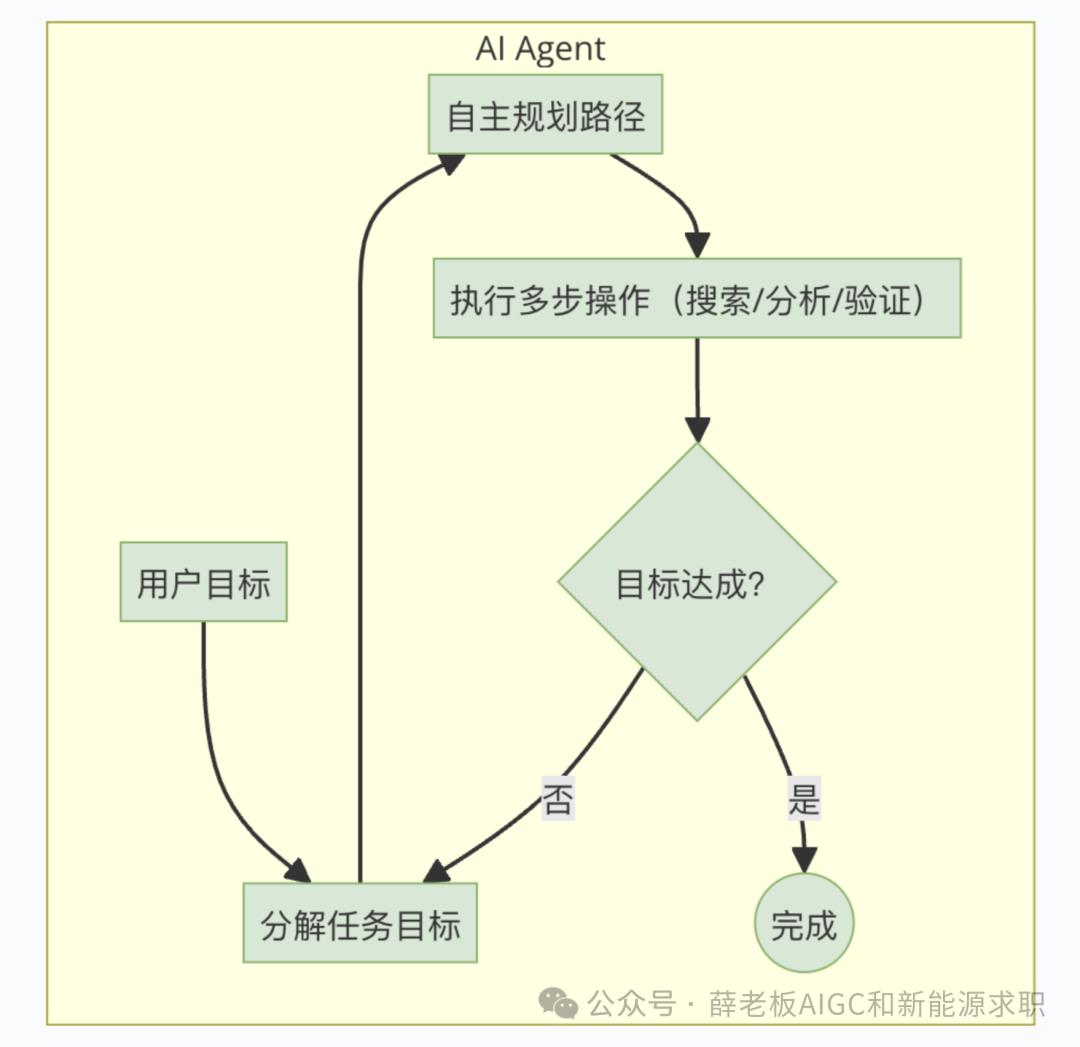
但AI Agent完全不同。如果你对它说:"帮我研究AI Agent的定义",它不会简单地回复一句话,而是会主动搜索资料、对比不同来源、分析关键信息,最终给你一份完整的分析报告。
用更形象的比喻来说:
普通AI:像一台自动贩卖机,你按下按钮,它就给你对应的商品。
AI Agent:像一位私人助理,你告诉它需求,它会自己规划步骤、执行任务,直到达成目标。
就像李宏毅教授所说,传统AI是"指令驱动",而AI Agent是"目标驱动"——你只需要指明方向,剩下的交给它来完成。

1.2 AI Agent 的定义和工作循环

目标设定 - 接收人类指令(如"赢得围棋比赛")
环境感知 - 获取当前状态(如扫描棋盘布局)
决策执行 - 采取具体行动(如在5-7位置落子)
反馈更新 - 观察行动结果(如对手的应对)
持续迭代 - 循环执行直至目标达成
以AlphaGo为例:
• 终极目标:取得胜利
• 实时输入:解析棋盘局势
• 战术输出:执行最优落子
• 动态调整:应对对手棋路
这种"感知-决策-行动-反馈"的运作机制,本质上模拟了人类解决问题的思维过程:分析现状、制定策略、实施方案、评估效果并持续优化。

1.3 为啥 AI Agent 跟强化学习(RL)有关?
熟悉机器学习的朋友可能会发现,这个运作机制似曾相识。
没错,它和强化学习(Reinforcement Learning)的核心逻辑高度吻合。强化学习的关键在于让AI通过不断尝试来优化"奖励值"——以AlphaGo为例,获胜时获得+1奖励,落败时得到-1惩罚,经过海量对局训练后,它就能掌握制胜策略。
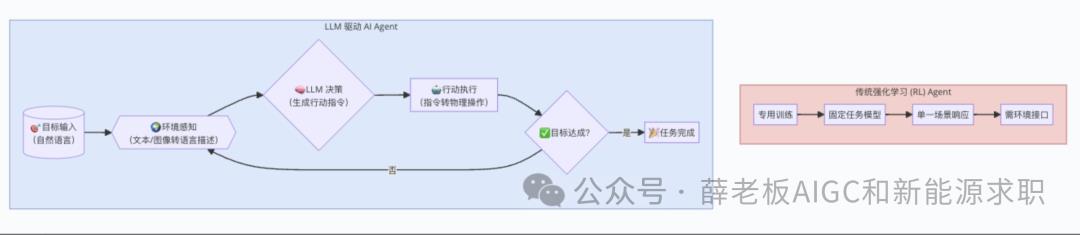
但传统AI Agent存在明显局限:它们通常是为单一任务专门训练的。比如专攻围棋的AlphaGo,如果要改下国际象棋,就得从零开始重新训练一个新模型,这种"一事一练"的模式显然不够灵活。
这正是当前AI Agent再度走红的关键突破——
现在我们有了更聪明的解决方案:直接让大语言模型(LLM)担任Agent的角色。这种新型Agent无需针对每个新任务重新训练,一个模型就能应对多种需求,真正实现了"一专多能"。
二、AI Agent 的「新灵魂」——大型语言模型(LLM)
2.1 LLM 如何变身 AI Agent?
传统基于强化学习的AI Agent存在明显的功能限制:每个模型只能执行特定任务。但随着大语言模型(LLM)的出现,游戏规则彻底改变了。
LLM最突出的优势在于其
多任务处理能力
——不仅能进行文本理解、智能问答、代码生成,还能实现跨模态的图文交互。
那么,能否直接让LLM担任AI Agent的角色呢?
实践证明完全可行!基于LLM的AI Agent是这样运作的:
文字化目标输入:
例如"请帮我赢得围棋比赛"环境信息文本/图像化:
棋盘状态可转为文字描述("黑子位于A1,白子位于B2")或直接输入棋盘图像文字指令输出:
LLM生成"建议在C3位置落子"的文本,由执行系统转化为实际操作动态迭代执行:
环境更新后,LLM持续观察并输出新的行动方案与强化学习的本质区别在于:LLM无需专门训练,仅凭其预训练获得的世界知识就能"推理"出合理行动方案。这种"开箱即用"的特性,让AI Agent的开发效率获得了质的飞跃。
2.2 LLM 做 Agent 的优缺点
优点
缺点
三、AI Agent 的三大关键能力
3.1 根据经验调整行为
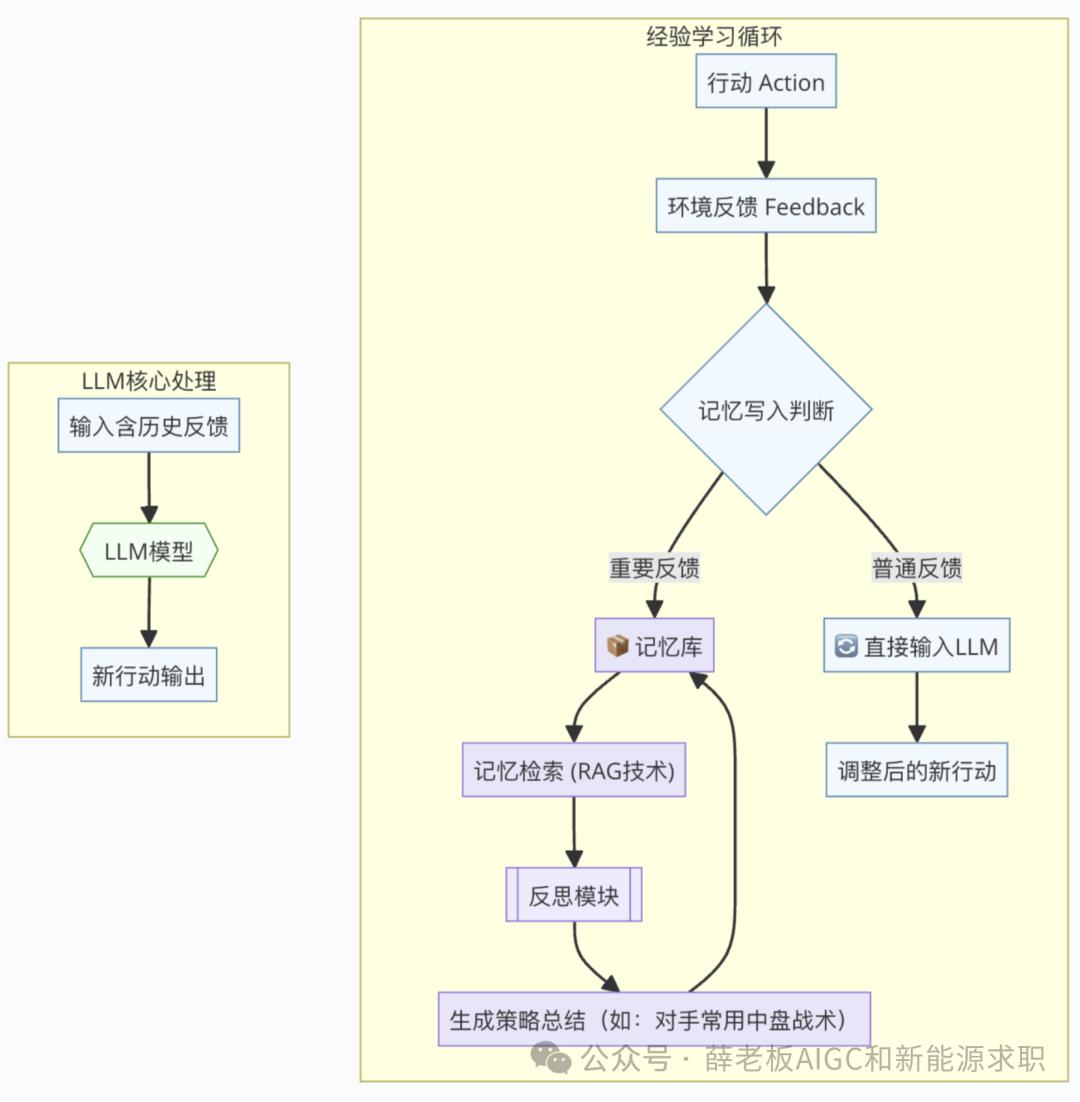
3.2 使用工具
用 Temperature(地点, 时间) 查温度。今天北京多热?[Tool] Temperature(北京, 现在) [Tool][Output] 28°C [Output]现在 28°C。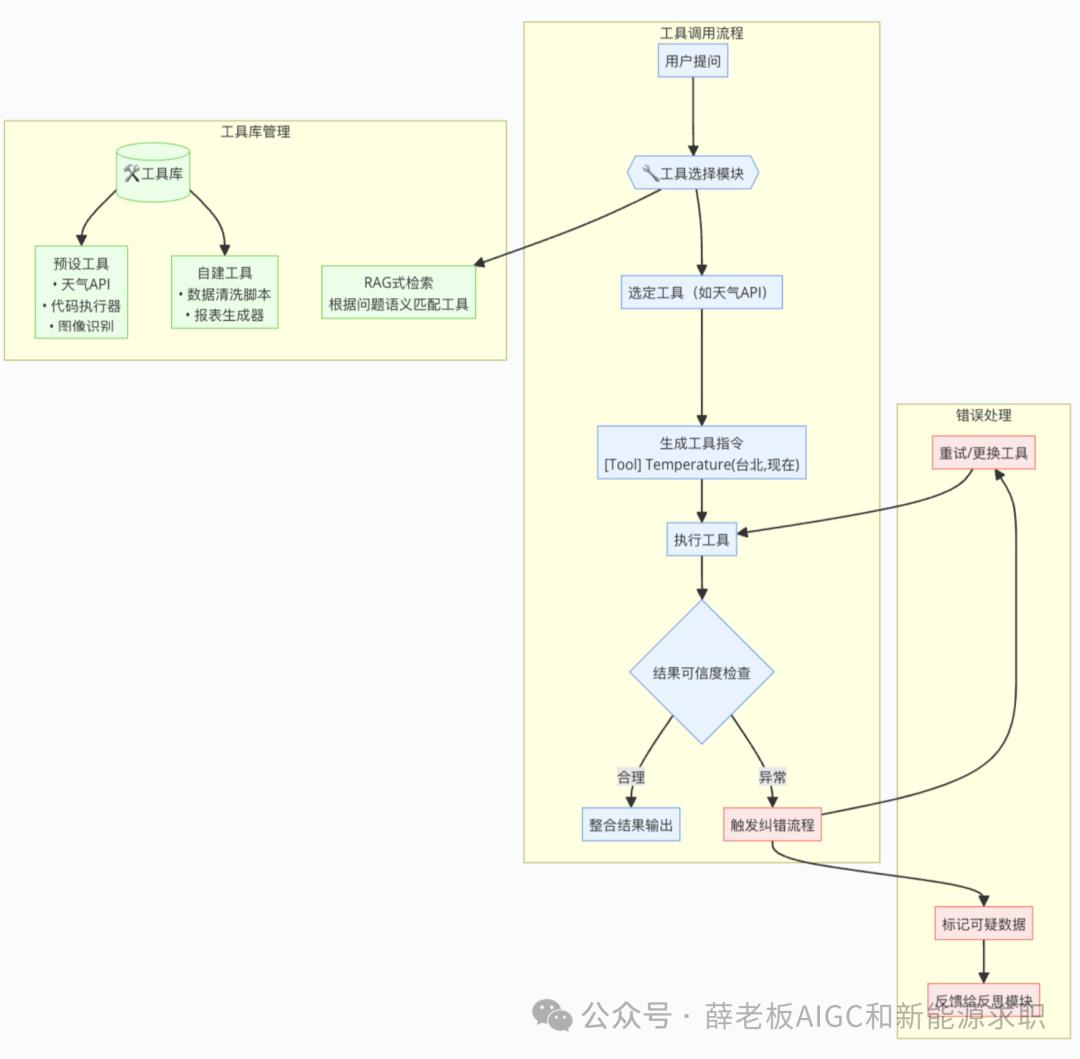
3.3 做计划
找牙刷 → 挤牙膏 → 刷 → 漱口。AI Agent 也得会规划,不然每步都随机试,太笨了。